🤖 AI 駆動開発でテスト技法の体系が必要な理由
TDD 編 では 「いつテストを書くか」 を扱いました。本記事は 「何をどうテストするか」 — テストの体系 — を扱います。
AI が生成するコードは速く・量が多い。これを 網羅的に検証する ためには、 テストレベル × テスト技法 の体系を持っておく必要があります。
| AI 駆動開発で起きる問題 | テスト技法が解決すること |
|---|---|
| AI が境界値で破綻する | 限界値分析・同値分割で系統的にカバー |
| AI が結合点で動かない | 結合テストで検出 |
| AI が画面操作で詰まる | E2E テストで検証 |
| 業務担当者の検収が通らない | UAT 設計で先回り |
| カバレッジが上がるが実バグが残る | 「正しさ」を測るテスト設計 |
本記事は開発手法ガイド:概要のシリーズ 6 本目。TDD 編の直後に位置づけ、テストレベルと技法を 1 本で俯瞰します。
🏗️ テストレベル — 「どこをテストするか」
4 階層
テストは 対象範囲の大きさ で 4 つのレベルに分かれます。
| レベル | 対象 | 速度 | 件数の目安 | 代表ツール |
|---|---|---|---|---|
| 単体テスト (Unit) | 関数・クラス単位 | 数 ms | 数千〜 | Jest / Vitest / xUnit / pytest |
| 結合テスト (Integration) | モジュール間 / DB / API 連携 | 数百 ms | 数百〜 | Testcontainers / Pact / MSW |
| システムテスト (E2E) | アプリ全体(ブラウザ操作含む) | 数秒〜 | 数十〜 | Playwright / Cypress / Selenium |
| 受入テスト (UAT) | 業務担当者の検収 | 人手 | シナリオ単位 | チェックシート / 受入仕様書 |
速度が下に行くほど遅く、件数も少なくなる — これが鉄則。AI 駆動開発では特に、 テストの実行速度がループ速度を決める ため、上位レベル(単体・結合)を厚く保つことが効きます。
テストピラミッド vs テストトロフィー
テストレベルの配分には 2 つの代表的な考え方があります。
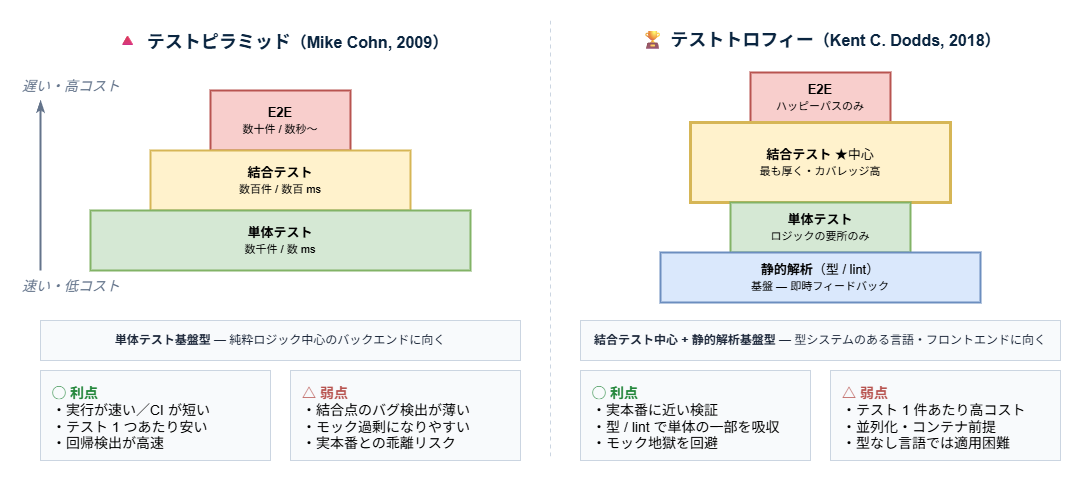
| モデル | 提唱者 | 特徴 |
|---|---|---|
| Testing Pyramid | Mike Cohn (2009) | 単体テスト基盤型 — 単体多め・E2E 少なめ。バックエンド向き |
| Testing Trophy | Kent C. Dodds (2018) | 結合テスト中心型 — 静的解析を基盤に置き、結合を厚く。フロントエンド・型ありの言語向き |
どちらを採るか
| 状況 | おすすめ |
|---|---|
| バックエンド(純粋ロジック多め) | Pyramid |
| フロントエンド / API 連携多め | Trophy |
| TypeScript / 型が厚い言語 | Trophy 寄り |
| AI 駆動開発で速度重視 | テスト実行が秒以内のレイヤーを厚く |
🔬 テスト技法 — 「どう網羅するか」
テスト技法は大きく ブラックボックス (仕様ベース)と ホワイトボックス (コードベース)に分かれます。
ブラックボックステスト(仕様ベース)
入力と出力の関係 = 仕様に基づいてテストケースを設計します。
| 技法 | 内容 | 使いどころ |
|---|---|---|
| 同値分割 | 入力を等価なクラスに分け、各クラスから 1 件ずつテスト | 入力空間が広い |
| 限界値分析 | 同値クラスの境界を集中的にテスト | バグは境界に集まる |
| デシジョンテーブル | 条件の組み合わせを表にして網羅 | ビジネスルールが複雑 |
| 状態遷移テスト | 状態 + 入力 → 次の状態の組み合わせを網羅 | ワークフロー / Saga |
限界値分析の具体例
「年齢が 18 以上 65 以下なら有効」という仕様:
同値分割:
無効クラス1: 17 以下
有効クラス: 18〜65
無効クラス2: 66 以上
限界値:
17, 18, 19, 64, 65, 66 を必ずテストバグはほぼ境界に集まる ため、限界値を確実にカバーすると検出率が劇的に上がります。AI に「網羅的にテストして」と任せると、限界値を忘れがちなので 「限界値分析と同値分割で」と明示 しましょう。
デシジョンテーブルの具体例
「会員ランク × 商品種別」で割引率が決まる場合:
| 会員ランク | 商品: 通常 | 商品: セール |
|---|---|---|
| ゴールド | 10% 割引 | 5% 割引 |
| 一般 | 0% | 0% |
4 ケース全てを必ずテスト 。条件が増えると組み合わせが指数的に増えるので、表で管理すると漏れない。
状態遷移テスト
注文の状態(受付 → 確定 → 出荷 → 完了)に対して、各遷移と「許可されない遷移」(出荷後に確定に戻すなど)を全網羅。 Saga パターン やイベントソーシングを扱う領域で必須。
ホワイトボックステスト(コードベース)
ソースコードの構造に基づいてテストケースを設計します。 カバレッジ指標 とも対応します。
| 技法 | 内容 | 対応するカバレッジ指標 |
|---|---|---|
| 命令網羅 (C0) | 全ての文を 1 回以上実行 | Statement Coverage |
| 分岐網羅 (C1) | 各 if の真偽両方を実行 | Branch Coverage |
| 条件網羅 (C2) | 各条件式の真偽組み合わせを網羅 | Condition Coverage |
| 経路網羅 (Path) | 全実行経路を網羅 | Path Coverage |
例: if (a > 0 && b > 0) のテスト
| 技法 | 必要なテストケース |
|---|---|
| 命令網羅 (C0) | a=1, b=1(true 経路)、a=0, b=0(false 経路)の 2 件 |
| 分岐網羅 (C1) | 上記 2 件で OK(分岐は真偽 2 種) |
| 条件網羅 (C2) | a=1/a=0 × b=1/b=0 の 4 件 |
| 経路網羅 | 全実行経路 — 規模が大きいと組み合わせ爆発 |
通常は C1(分岐網羅) を最低基準に、複雑なロジックは C2 まで上げる、という運用。
MC/DC(Modified Condition/Decision Coverage)
航空・医療など 安全要件が厳しい領域 で求められる、各条件が独立して結果に影響することを示すカバレッジ。一般業務では不要ですが、 「条件網羅より厳格な指標がある」 という認識は持っておくと役立ちます。
その他のテスト技法
| 技法 | 内容 | ツール例 |
|---|---|---|
| 探索的テスト | テスト計画なしに、感覚で穴を探す | 人間の経験 |
| プロパティベーステスト | 入力をランダム生成、性質を検証 | QuickCheck / fast-check |
| 性能テスト | 負荷・ストレス・ボトルネック特定 | k6 / Gatling / JMeter |
| セキュリティテスト | OWASP Top 10、ペネトレーションテスト | OWASP ZAP / Burp Suite |
| アクセシビリティテスト | WCAG 準拠確認 | axe-core / Lighthouse |
🎭 テストダブル — 依存を分離する道具
単体テスト・結合テストでは、外部依存(DB・API・時刻・乱数)を テストダブル に差し替えるのが定石。
5 種類のテストダブル
| 種類 | 役割 | 例 |
|---|---|---|
| Stub | 決め打ちの値を返すだけ | getUser() が常に固定ユーザーを返す |
| Mock | 呼び出された事実を 検証する | 「save が 1 回呼ばれた」を assert |
| Spy | 呼び出しを記録するだけ(事後検証) | テスト後に「何回呼ばれたか」を見る |
| Fake | 簡易実装(インメモリ DB 等) | InMemoryRepository |
| Dummy | 引数を埋めるためだけのオブジェクト | null 代わりの空クラス |
Mock vs Spy の違い
Mock(事前期待):
expect(repo).toHaveBeenCalledWith(order) // 期待を先に書く
→ 期待外の呼び出しがあれば即失敗
Spy(事後検証):
// テスト本体
expect(spy.callCount).toBe(1) // 後から確認
→ 柔軟だが、検証漏れの危険ありFake が一番強い
| 観点 | Mock / Stub | Fake |
|---|---|---|
| 本物への忠実度 | 低(事前にハードコード) | 高(簡易実装で振る舞う) |
| テストの保守性 | API が変わると全壊 | API が変わっても追従可能 |
| 速度 | 速い | 速い |
| AI 駆動開発との相性 | △ | ◎ |
リポジトリパターン で IOrderRepository を切り、 InMemoryOrderRepository を Fake として実装すれば、 DB 起動なしで業務ロジックを単体テスト可能 。AI ループが秒で回ります。
📊 カバレッジ — 何を測るか
カバレッジの種類
| 指標 | 何を測るか |
|---|---|
| Statement Coverage (C0) | 各文を実行 |
| Branch Coverage (C1) | 各分岐を実行 |
| Condition Coverage (C2) | 各条件式の真偽 |
| Function Coverage | 各関数を呼び出し |
| Line Coverage | 各行を実行 |
カバレッジの罠
カバレッジ 100% でもバグはある。カバレッジが上がるテスト ≠ 良いテスト。
カバレッジは 「コードのどこが実行されたか」 を測るだけで、 「正しい振る舞いか」 は測りません。
| ありがちな失敗 | 結果 |
|---|---|
| カバレッジを目標化 | assert なしのテスト量産(実行はするが検証しない) |
| カバレッジ 100% で安心 | 限界値・例外パスが抜けてもバグ発覚せず |
| カバレッジが下がるたびに無理に上げる | 重要でない箇所のテストが増える |
健全な閾値
| レベル | 推奨カバレッジ |
|---|---|
| 単体テスト | 80%+(コアロジックは 95%+) |
| 結合テスト | 60%+ |
| E2E テスト | ハッピーパスのみ網羅すれば十分 |
CI への組み込み
- カバレッジ低下する PR は 自動却下 (Jest threshold / coverlet threshold)
- 新規コードは カバレッジ閾値を厳しめ に(既存負債は段階的に)
- 業務上重要な箇所 のカバレッジを別管理(タグ付け)
🇯 UAT(受入テスト) — 業務担当者との橋渡し
UAT の本質
UAT は 開発者ではなく業務担当者 が「業務として OK か」を判定するテスト。
- 仕様通りでも、業務に合わなければ NG
- 業務フローと矛盾するシステム挙動を検出
- 「現場で使えるか」を確認する最後の関門
UAT を設計する 3 つの型
1. シナリオベース
業務フロー単位で受入条件を作る:
シナリオ: 注文受付 〜 決済完了まで
前提: ログイン済み・カートに商品あり
手順: 1) 配送先入力 2) 決済方法選択 3) 注文確定
結果: 確定メール受信、在庫が引き当てられている2. ユーザーストーリー(Given / When / Then)
Given 在庫 5 個の商品がカートに入っている
When 数量を 6 個に変更しようとする
Then 「在庫不足」エラーが表示される3. 受入条件チェックリスト
[ ] 注文確定後、在庫が即座に減る
[ ] 確定メールが 1 分以内に届く
[ ] キャンセル時に在庫が戻る
[ ] 決済失敗時に注文が確定しないAI 駆動開発との接続
UAT は 要件定義時点で設計 すると効きます。 ステアリング駆動開発 の requirements.md に 受入テストシナリオ を書いておけば、AI に実装を任せても 「受入条件を満たすか」 を Given/When/Then で検証できます。
業務担当者から UAT シナリオを引き出すのも 要件定義の一部 。これは ビジネスケイパビリティ の理解と対になる活動です。
🎯 AI 駆動開発でのテスト戦略
どのレイヤーを AI に任せやすいか
| レイヤー | AI への任せやすさ | 理由 |
|---|---|---|
| 単体テスト | ◎ | 入出力が明確、AI が網羅的に書ける |
| 結合テスト | ○ | 設定が複雑、人間が骨組みを作る |
| E2E テスト | △ | UI 変更で頻繁に壊れる、慎重な設計が必要 |
| UAT | × | 業務担当者の判断が必要 |
AI に渡すと効く指示テンプレート
レベル: 単体テスト
対象: PriceCalculator.applyDiscount()
技法: 限界値分析 + 同値分割
網羅: 0 円 / 1 円 / 9999 円 / 10000 円 / 100 万円 / 負数 / 小数
ダブル: なし(純粋関数)レベル: 結合テスト
対象: OrderService → PostgresOrderRepository
技法: Testcontainers で本物の PostgreSQL 起動
網羅: 注文確定 / 重複注文の排他 / トランザクション失敗時のロールバックよくある失敗
| 失敗 | 是正 |
|---|---|
| カバレッジ 100% を目標化 | 「業務上重要な箇所」を別タグで管理。100% より 80% + 重要箇所 100% |
| 単体だけで安心 | 結合点(DB / API)で破綻するため、結合テストを必須化 |
| E2E だけで担保 | 実行が遅く AI ループが回らない。単体・結合を厚く |
| モック過剰 | 「テストは通るが本物では壊れる」状態に。Fake を優先、境界だけ Mock |
| ハッピーパスばかり | 「限界値・例外パスを必ずカバーして」と AI に明示 |
⚠️ アンチパターン
1. テストレベルの偏り
単体だけ厚い → 結合点で破綻。E2E だけ厚い → 実行が遅く AI ループが回らない。
是正: テストピラミッド or トロフィーを 意識して配分 。AI 駆動開発では「秒で回るレイヤーを厚く」が鉄則。
2. 限界値・境界値を忘れる
AI に「テスト書いて」だけだと、ハッピーパスばかり書かれる。
是正: 「限界値分析と同値分割で網羅して」と明示。境界値リストを人間が事前に渡す。
3. デシジョンテーブルなしに条件分岐をテスト
条件の組み合わせが増えると、テスト漏れが指数的に増える。
是正: ビジネスルールは デシジョンテーブルで網羅性を担保 。表を AI に渡してテスト生成させる。
4. UAT を最後に押し付ける
リリース直前に業務担当者にチェックしてもらい、根本的な認識ずれが発覚 → 大量手戻り。
是正: UAT シナリオを 要件定義時点で作成 。ステアリングの requirements.md に受入条件を書く。
5. テストの実行が遅い
AI ループが回らない、CI が長い、開発体験が悪化。
是正: 単体は 数 ms 、結合は並列化、E2E はハッピーパスのみ。CI も並列実行で高速化。
6. テストダブルが「Mock 一辺倒」
API 変更で全テストが壊れる、メンテナンスコスト爆発。
是正: Fake を優先 。境界(DB / 外部 API)だけ Mock。 リポジトリパターン でドメイン層を Fake で単体テスト。
📚 まとめ
- テストは レベル(縦軸) × 技法(横軸) で考える
- レベル: 単体 → 結合 → E2E → UAT。 下に行くほど遅く、件数も減らす
- 配分は Pyramid(古典)か Trophy(現代)。AI 駆動開発では 「秒で回るレイヤーを厚く」 が鉄則
- ブラックボックス: 同値分割・限界値分析・デシジョンテーブル・状態遷移
- ホワイトボックス: 命令網羅・分岐網羅・条件網羅 (カバレッジ指標と対応)
- テストダブル 5 種を理解し、 Fake 優先・境界だけ Mock
- カバレッジは 目的ではなく指標 。100% より「業務上重要な箇所」を確実に
- UAT は 要件定義時点で設計 。
requirements.mdに Given/When/Then で書く - AI に任せやすいのは 単体テスト 。結合・E2E は人間が骨組み、UAT は業務担当者の判断
🔗 関連記事
- 開発手法ガイド:概要 — シリーズ全体の位置づけ
- 開発手法ガイド:TDD 編 — いつテストを書くか(本記事は「何をどう」を扱う)
- 開発手法ガイド:DDD 編 — テスト対象となる業務ルールの設計
- 開発手法ガイド:SOLID 原則編 — テストしやすい設計を支える原則
- ステアリング駆動開発 — UAT を要件定義に組み込むワークフロー
📖 関連用語
テストレベル
テスト技法
テストダブル
- テストダブル — Stub / Mock / Spy / Fake / Dummy の体系
配分モデル
設計と業務側
- SOLID 原則 — テスト容易性を支える設計原則
- リポジトリパターン — Fake への差し替えで単体テスト高速化
- ヘキサゴナルアーキテクチャ — アダプタを差し替えてレイヤー別テスト
- DDD — テスト対象を業務ドメインで切る
- ビジネスケイパビリティ — UAT シナリオの単位
- Saga パターン — 状態遷移テストの典型対象
📎 参考資料
- Testing Pyramid — Mike Cohn
- Testing Trophy — Kent C. Dodds
- ISTQB Foundation Level Syllabus(テスト技法の国際標準)